
This is a continuation of my series on site performance. If your organization is struggling with alignment on “site speed,” consider reading Speed first.
Rhombic Networks
In an uncomfortably hot conference room, not so far away, there is a technical team brainstorming strategies for improving their web performance. Their existing on-premise servers seem to handle the load most of the time, but occasionally their site goes down because of planned paid traffic spikes and email campaigns.
They consider adding an additional five delivery severs, but that seems wasteful since the three they have handle the traffic 95% of the time. They know this request will not get approved due to the additional cost. One teammate suggests implementing a Content Delivery Network (CDN), but others do not understand the benefits. The meeting ends with a single action item – ask the content team to start uploading optimized images.
Hosting
Hosting decisions typically end up being a balance between two things: cost and team skillset, in that unfortunate order. I do not take into account the team’s bandwidth as it requires the same amount of overhead. Managed services can alleviate some of this, but it does not completely go away.
At the enterprise-level, you are likely working with Azure, AWS, or Google Cloud. Each has its own unique services and it is crucial to identify which aligns with your application. Figure 1 illustrates the difference between on-premise, Infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS), and software-as-a-service (SaaS). Even this graphic is a bit misleading since you do stop managing parts of the stack, you do still need to configure things. Simply moving to the cloud does not lower the amount of work your team spends managing the environment. Do not let a salesperson convince you of this. There are plenty of good reasons to move to the cloud, this just isn’t one of them.

IaaS and PaaS are often the candidates for migrating your on-premise solution. In layman terms, think of IaaS as virtual machines where you still need to install and configure the software. PaaS takes out managing the operating system and you spend your time configuring and tuning your platform. SaaS should be in its own category. When thinking of SaaS, think of Netflix, Office 365, or Dropbox.
Hybrid Approach
Moving to the cloud can be overwhelming, especially if you do not have a vendor or team with the skills to manage it. Budgeting, complicated integrations, and timelines impact these decisions, which happens to be Rhombic Network’s situation. Here is where I will often recommend a hybrid approach (Figure 2).

I have significantly simplified this, but the hybrid configuration allows you to leave most of your on-premise infrastructure and integrations intact while moving your delivery environments to IaaS or PaaS with your chosen provider. In my example, we chose Azure. This solves the following problems for Rhombic, our fictitious company:
- Ability to more easily scale delivery servers when needed
- Small cloud provider spend
- Delivery environments moved to a datacenter, thus better network speeds than the servers in the company basement
- The team gets exposure to the selected cloud provider
Scaling
We aren’t talking about fish! Scaling is the ability to expand or contract our capacity based on demand. This is the pay-for-what-you-use selling point in leveraging a cloud provider.
Consider what happens when Rhombic pushes 500,000 emails over an hour with a link to your summer sale landing page. Or perhaps they spend 200 million dollars on a Facebook ad. Do you think your website can handle that?
For these scenarios, I would consider planned scaling. This means adding capacity just prior to known demand spikes. Based on previous email campaigns, Rhombic knows they need to expand capacity by 200% for a 2pm email drop. Using Figure 3 as an example, they can simply expand to six delivery environments. This is not typically a feasible task in an on-premise setup.

So what about organic capacity changes, such as time-of-day? These can easily be handled with autoscaling. This is configurable and varies based on your deployment model and provider. In fact, after Rhombic added their additional capacity, the rules they set for auto-scaling slowly reduced the number of environments as the demand dropped.
Now, you may be wondering why have planned scaling if you already have autoscaling. Autoscaling is great for slow to moderate changes in demand; however, it does take time for the new environment to spin up. When Rhombic spins up new environments, it takes 10 minutes before they become available. So in a best case scenario, autoscaling might be able to support the email spike in 10 minutes while the existing environments are overwhelmed. Obviously, this is not ideal. This is why planned spikes in demand should be supported by planned scaling.
Of course, scaling doesn’t just apply to your front-end delivery environments; it can apply all portions of your web ecosystem.
The last thing I want to mention is the concept of horizontal versus vertical scaling. We have been talking about horizontal scaling, which is adding more capacity by creating new instances. Vertical scaling is adding more physical resources to an existing instance such as CPU and RAM. In my experience, vertical scaling is more often for permanent changes where horizontal scaling makes more sense for dynamic capacity.
Application Performance
Rhombic Networks has a single scrum team and they are focused on delivering value to the business. There isn’t time to pay down technical debt. Performance issues are only addressed if a stakeholder complains. Most recently, their search page, which has filters for their many products, takes approximately 20 seconds to load after each selection.
I’ll get right to the point. Successful businesses and teams do the following:
- Make time to pay down technical debt
- Invest in the proper tooling
Without these, you might as well be trying to replace a toilet with one hand behind your back and a roll of duct tape.
In Rhombic’s case, the development team was given time to learn how to debug their live Azure instance, identified the offending code, and refactored it. The component had previously made 17 requests directly to the database for each filter option which was the issue. Now it stores the taxonomy in the browsers shadow DOM, uses optimized indexes, and is caching database and query results. Results appear in 300ms or less. This change resulted in a 30% increase in conversions when using the product search page.
Application Performance Monitoring
Rhombic Networks averages two production incidents per month. One lasted several hours resulting in lost revenue of approximately 40k dollars. Quite often, it is a customer contacting Rhombic and raising the flag. When this happens, the entire team drops what they are doing and immediately follows their emergency playbook which is taped on their cubical walls. One team member calls the hosting provider, another calls the CMS product support, and a third struggles to log in to the overwhelmed delivery servers to check the logs. Eventually, they are able to log in and reboot the machine – seemingly fixing the issue. No further investigation is done.
There is a better way of handling this. Application Performance Monitoring (APM) tools, such as Dyantrace, keep a close eye on your environment for you. Some folks are happy with an uptime monitor that checks for a 200 response, but that is not enough for revenue-generating sites. APMs will monitor the health of your application, check your logs, network connections, etc. Imagine having a synthetic user testing your lead entry form every 5 minutes from 15 places around the globe. What if it could tell you when there are spikes in traffic, unusual changes in CPU, or can identify a line of code that is causing performance issues?
This is a real thing. You can have one too.
There are quite a few other tools in this space, but I happen to be most familiar with Dynatrace as a former customer. I remain a dedicated fanboy, but I am in no way affiliated with them.
Caching Strategy
Ask any database administrator, .NET developer, or Front-End developer about their caching strategy and you often get three different answers. You need a holistic caching strategy – a high-level document outlining when and where things are cached. This can be used when troubleshooting issues and also to identify areas requiring further optimization.
We will not delve into the nuances of database caching or output caching as this is different between technologies and software. Just know that you should do both. Next, we will look at how we can use a content delivery network.
Content Delivery Network
Content Delivery Networks (CDNs) are not just for caching your images, they perform a multitude of optimization services. This blog is using Cloudflare. Some of the services I have available to me include:
- Image optimization and resizing
- Auto minification of JavaScript, CSS, and HTML
- Plain text compression – Brolti can save you up to 20% over gzip
- TLS/SSL certificates
- Web Application Firewall (WAF)
- Intelligent page caching
Basic CDN features are extremely inexpensive, in fact, Cloudflare offers a free tier. Everyone should be taking advantage of these performance gains.
Akamai is a more enterprise-level CDN with in-depth reporting features and can even optimize images based on what device you are on. For example, the most optimized image for an iPhone might be a different format of JPEG than the one for Android and it will deliver the appropriate image. How crazy is that?!
Regardless of all these other features, the original purpose of CDN’s was to get content closer to your end-user. They achieve this by distributing their edge servers across the globe. For example, let’s assume Rhombic has just implemented a CDN and their web servers sit in a Seattle datacenter. When a user in Manchester visits the Rhombic Networks website, the cached files will be served from the CDN’s Boston edge server instead of going back to the origin in Seattle as illustrated in Figure 4.
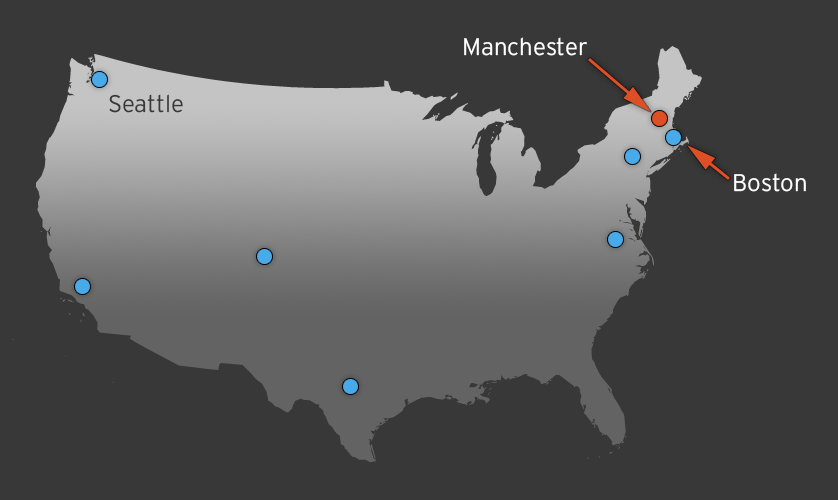
This shorter distance can save hundreds of milliseconds per request. For instance, this blog was taking almost 3 seconds to load prior to implementing the CDN and now I am consistently getting full page loads under 400ms.
CDN Page-level Strategy
I see many enterprise-level CDN implementations and often notice they are not maximizing their technology investment. Let’s look at a basic page-level strategy.
Rhombic Networks has the following site structure:
-
Home Page
-
Products
- Samat Bobblehead
- Misha Bobblehead
- Greg Bobblehead
- Product N
-
News
- Article 1
- Article 2
- Article N
-
Landing Pages
- LP 1
- LP 2
- LP N
- About Us
- Careers
- Privacy Policy
-
Products
Rhombic is already caching their images, JavaScript, and CSS, but they can optimize further. There are 2 to 3 news articles published a week and the content is not changed once it is posted. Similarly, the landing pages created are used for events and contain static information. These pages are perfect candidates to 100% cache on the edge servers. Not only does this reduce the load on your origin servers, but it will also be significantly faster for your end-users. Which other pages do you think we should cache in this example?
Again, this is one of the most basic features of a CDN. I encourage you to work with your CDN to identify other opportunities for optimization.
How to Get Started
This post is designed to get you through some of the basic concepts and by no means covers everything. I highly recommend engaging a reputable partner or vendor if you struggle with any of these.
Of the issues covered, implementing an APM is the quickest win. Doing this first can help you create a healthy backlog of application improvements. If you do not have a CDN, I would consider this the next priority. This process is absolutely more involved, but implementing even the basic features will provide immediate results.
Stay tuned for my next post where I will cover Sitecore-specific optimization strategies. Never stop optimizing!
Leave a Reply